Hi,
ich versuche mich gerade an einem ER-Diagramm und bastel es in Access 2007 (nur aus gründen der Ansicht).
Ich versuche mein Problem mal zu schildern (Inhalt und Thema fiktiv):
Tabellen:
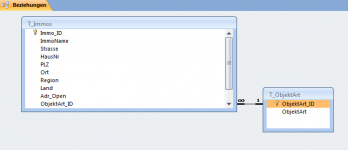
T_Immos
T_ObjektArt
(zu betrachten im angehangenden Bild (ER-1.png) )
Wie man in der Tabelle "T_Immos" sieht, sind dort nur rudimentäre Eigenschaften enthalten, die jede Art von Immobilie betreffen.
Mein Problem liegt nun darin, dass ich zu jeder Immobilien/Objektart verschiedene Eigenschaft brauch.
Habe ich nun einen "Laden", brauche ich die Eigenschaft "Länge Fensterfront" z.B. ...
Habe ich eine Mehrfamilienhaus, brauche ich z.B. die Eigenschaft "Zugang zum Garten möglich?" ...
Diese verschiedenen Eigenschaften zu einer Immobilie resultieren also aus der ausgewählten ObjektArt.
Mein Problem ist nun der Aufbau/Beziehung des ER-Diagramms zu meinem Problem.
Mein Ansatz ist, eine Tabelle in folgder Form zu erstellen:
T_Eigenschaften
--------------------------------------
ObejktArt_ID | Eigenschaften
--------------------------------------
T_Immos -> auffüllen mit alles Eigenschaften (standardwert = 0)
Bei der späteren Eingabe müssten sich aber die Eingabefelder anhand der ObjektArt ändern und in die entsprechenden Felder der Tabelle T_Immos einschreiben.
Und da harperts bei mir mit dem Verständniss.
Ich hab da glaube grad auch zu lange drüber nachgedacht, komme immer aufs selbe.
ich versuche mich gerade an einem ER-Diagramm und bastel es in Access 2007 (nur aus gründen der Ansicht).
Ich versuche mein Problem mal zu schildern (Inhalt und Thema fiktiv):
Tabellen:
T_Immos
T_ObjektArt
(zu betrachten im angehangenden Bild (ER-1.png) )
Wie man in der Tabelle "T_Immos" sieht, sind dort nur rudimentäre Eigenschaften enthalten, die jede Art von Immobilie betreffen.
Mein Problem liegt nun darin, dass ich zu jeder Immobilien/Objektart verschiedene Eigenschaft brauch.
Habe ich nun einen "Laden", brauche ich die Eigenschaft "Länge Fensterfront" z.B. ...
Habe ich eine Mehrfamilienhaus, brauche ich z.B. die Eigenschaft "Zugang zum Garten möglich?" ...
Diese verschiedenen Eigenschaften zu einer Immobilie resultieren also aus der ausgewählten ObjektArt.
Mein Problem ist nun der Aufbau/Beziehung des ER-Diagramms zu meinem Problem.
Mein Ansatz ist, eine Tabelle in folgder Form zu erstellen:
T_Eigenschaften
--------------------------------------
ObejktArt_ID | Eigenschaften
--------------------------------------
T_Immos -> auffüllen mit alles Eigenschaften (standardwert = 0)
Bei der späteren Eingabe müssten sich aber die Eingabefelder anhand der ObjektArt ändern und in die entsprechenden Felder der Tabelle T_Immos einschreiben.
Und da harperts bei mir mit dem Verständniss.
Ich hab da glaube grad auch zu lange drüber nachgedacht, komme immer aufs selbe.
") Bei Linux isses meistens schon dabei. Unter Windows kannst du es aber auch betreiben.
Bei Linux isses meistens schon dabei. Unter Windows kannst du es aber auch betreiben.